Jottings¶
In an ideal world, I’d have time to write all the things about muddle that need writing down. This doesn’t seem to be that world.
This section of the documentation is where I shall try to put useful notes - more or less what is typically called “Frequently Asked Questions”, except that that seems to rather a high standard to aim for.
bash: <toolchain>/bin/arm-none-linux-gnueabi-gcc: No such file or directory¶
This isn’t really a muddle issue, but it’s very confusing when it happens.
What this normally means is that your are running 64-bit operating system
(e.g., Ubuntu), but the toolchain has been built for 32-bit. The solution
for Debian derived systems is normally to install ia32-libs:
sudo apt-get install ia32-libs
which provide compatibility.
It might be nice to put this into an aptget clause in the build
description, but I’m not sure what happens if you attempt to install
ia32-libs on a 32-bit OS.
./autogen.sh: line 3: autoreconf: command not found¶
And this one means you need to install autoconf (for the GNU autotools):
sudo apt-get install autoconf
So what should I apt-get install?¶
Clearly one normally needs build-essentials, which provides C and C++
compilers, GNU make and suchlike.
Future versions of muddle are likely to take advantage of rsync, if its
installed, to speed up copying of files.
Building the kernel is likely to want you to install lzma, which is
unobvious.
If you insist on using udev (busybox’s mdev is smaller and simpler to
use, but you might not have a choice), then you’ll probably have to install
docbook-xsl, even if you try your hardest to stop it building any
documentation.
It’s not uncommon for FSF packages to insist of texinfo, even if you’re
trying not to build documentation. You may also need to install autotool
and libtool.
bash or dash?¶
Current Ubuntu systems (is it all Debian derived systems?) default to
/bin/sh being dash, rather than bash.
dash is a Posix compliant shell. It’s much smaller than bash, and arguably
simpler to understand.
bash is a monster, with inaccurate documentation, but it is the norm on
many Linux distributions (and on Mac OS X).
Many software packages assume bash in their build scripts and Makefiles. FSF
packages do so explicitly. It is also quite easy to accidentally require bash
when writing shell scripts, as we’re not normally conscious of where its
extensions start. Unfortunatley, many of those same shell scripts start with
#! /bin/sh when what they mean is #! /bin/bash.
(A relatively common example of this is when scripts useecho -e, which is a valid switch for bash’s built inecho, but not that in dash. Of course, another solution for this specific problem would be for the script to use the systemecho, in/bin/echo, which probably does support-e.)
Unfortunately this means that building on Linux typically requires one to
replace sh meaning dash with sh meaning bash.
To check, do:
$ ls -l /bin/sh
lrwxrwxrwx 1 root root 4 2012-01-04 16:52 /bin/sh -> bash
...you can see I’d already done the conversion.
There are two “obvious” ways of fixing this:
Reconfigure dash:
$ sudo dpkg-reconfigure dash
and answer “no” when asked if it should install dash as
/bin/sh.Do it by hand (but please think about the commands before typing them, in case I got them wrong...):
$ cd /bin $ sudo ln -sf bash sh $ ls -l sh
There’s an argument to say that, if some of the Makefiles or build scripts in
the system really do care, it is a good idea to test for this in the build
description, and give an “up front” error, rather than a confusing
A similar sort of thing to check that /bin/sh is a link to bash may
also be worth doing - something like:
if os.path.realpath('/bin/sh') == '/bin/dash':
raise GiveUp('/bin/sh is linked to dash, not bash - this will not work for some scripts')
or you might prefer to test on != '/bin/bash'. Neither is particularly
elegant.
Why didn’t my deploy directory change?¶
The deploy directory (or, in other words, deployments) are treated
differently than the rest of the build infrastructure.
When you do muddle build of a package, it generally works something like:
- take the sources from the appropriate checkouts in the
srcdirectory - build in the appropriate
objdirectory - copy useful stuff to the appropriate
installdirectory
muddle rebuild, muddle distrebuild and so on all do variations on this
sequence. None of them touch the deploy directory and its contents.
The commands that do are:
the commands in the “deployment” categorie (see
muddle help categories):muddle deployandmuddle redeploymuddle cleandeploy
muddleat the top level, when there are default deployments defined in the build description.This last is because
muddleat the top level is equivalent tomuddle buildlabel _default_deployments _default_roles- that is, it will build the default deployments (but not any that are not default deployments).
If one is just building a build tree that one was given, then the build
description should (hopefully!) have been written so that muddle at the
top level does the right thing, producing the deployments that a normal user
wants.
If one is developing within a build tree, however, redeploying is expected to
be a rarer thing - one is normally doing the build/fix/build cycle until
everything works, and all the depedencies appear to be correct, and then one
redeploys. In this context, the deploy directory contains “the stuff to be
deployed on the target board” (or whatever the target might be), and one
doesn’t expect to generate this until everything (more or less) appears to be
building correctly.
How do I pull in a “meta” checkout?¶
Sometimes one has a “meta” checkout, which contains information that isn’t
actually built, but one always wants present. A typical example is a
src/docs/ directory, containing documentation.
The simplest way to make this always present is to use a fragment like the following:
checkouts.simple.relative(builder, co_name='docs')
null_pkg = null_package(builder, name='meta', role='meta')
package_depends_on_checkout(builder.ruleset,
pkg_name='meta', role_name='meta',
co_name='docs')
# And add it to our default roles
builder.add_default_role('meta')
in your build description.
This says:
- we have a simple checkout called
docs - we have a NULL package, called
meta, in role{meta}. A NULL package has “empty” rules for how to build it, so it will never actually do anything. - we make this NULL package depend on the checkout (and if we had other “meta”
checkouts, we could make it depend on each of those as well, so you only
need one
package:meta{meta}) - and we add the
{meta}role as one of our default roles. It will thus be built by a baremuddlecommand at the top of the build tree, which is normally how people build the whole tree.
Of course, just declaring the checkout means that muddle checkout _all
would pull it out, but pulling it in via a default role makes it even more
likely that the docs directory will get instantiated.
Build out-of-tree. Please.¶
We recommend going to lengths to do all builds out-of-tree.
That is, don’t build in the checkout directory, build in the obj/ directory for your package.
There are two main reasons for doing this:
- The traditional reason for building out of tree is that it allows one to build for several different configurations, and this is especially important in a muddle build, where one may build a single package in more than one role. Indeed, it’s not uncommon to build a package for more than one architecture.
- The other reason is clarity and simplicity. It’s very useful to have all
build artefacts sequestered from the original code. And moreover, this
works best when using version control systems as well. If the build
scatters files around in the checkout source directory, you’re going to
have to amend the .gitignore` file (or equivelant) so the VCS doesn’t
think there are un-checked-in files around. And
muddle pushis deliberately cautious about pushing in such circumstances. - The final reason is that you can recursively delete the
obj/directory and know you’ve got rid of build artefacts. Which is uncommonly useful.
Many packages are quite capable of building out-of-tree (and many, for instance the Linux kernel, actively recommend it themselves).
However, if you have to build a checkout that does not support it (sadly, KBUS
has been a problem here), then the simple and obvious solution is to use
$(MUDDLE) copywithout and just copy the whole source tree (or those bits
needed) into the obj/ tree.
So, for instance, from a Makefile.muddle for zlib:
config:
-rm -rf $(MUDDLE_OBJ_OBJ)
-mkdir -p $(MUDDLE_OBJ_OBJ)
$(MUDDLE) copywithout $(MUDDLE_SRC) $(MUDDLE_OBJ_OBJ) .git
(cd $(MUDDLE_OBJ_OBJ); ./configure --shared)
How do I get back to a clean checkout state?¶
The following strongly assumes all your builds are out-of-tree (see above).
If you understand how muddle works (see the chapter on “muddle and its directories”), then it should be obvious that you want to do:
$ rm -rf obj/ install/ deploy/
$ rm -rf .muddle/tags/package .muddle/tags/deployment
(for some value of “obvious”). Unfortunately, it is very easy to get this
wrong (I’ve accidentally deleted my src/ directory before now), and also
this doesn’t take account of any subdomains in a build tree.
The solution is the muddle command:
$ muddle veryclean
which does exactly those operations in a simple build, but also recurses
through subdomains if necessary (see muddle help veryclean for details).
This approach is to be preferred to:
muddle distclean _all
muddle cleandeploy
because the first actually only obeys the “distclean” target in each Makefile.muddle, which won’t necessarily do what (or as much) as you want.
How do I build my kernel?¶
Muddle has a special bit of infrastructure advertised for building the Linux kernel. It seemed like a good idea at the time, but it’s overcomplex and doesn’t work well for cross-compilation. So we now recommend something like the following:
Keep your kernel source tree as a GIT checkout. If you need to do any patches, do them directly into that checkout (don’t, for instance, keep a directory of patches and try to apply them. We’ve tried this, it doesn’t scale, and heh, it’s actually what GIT automates for you. We tried it so you didn’t need to.). Use branches to describe what you’re doing as well. In other words, treat your local version of the kernel source tree just like normal kernel developers do.
The following fragment of a build description may be a useful guideline. We’re assuming cross-compiling for ARM here.
We start with some useful headers and constants:
import muddled.pkgs.make as make import muddled.pkg as pkg from muddled.utils import LabelType, LabelTag # The name of the kernel checkout, and which branch we're using therein # (note that this is likely the only branch that will get cloned) LINUX_CHECKOUT_BRANCH = 'linux-3.2.0' # Kernel config - obviously this needs to name an existing file! TARGET_KERNEL_CONFIG = 'arch/arm/configs/some_evm_defconfig'
and then later on actually define the kernel:
make.twolevel(builder, 'kernel', roles=['base'], co_dir='base', co_name='kernel', branch=LINUX_CHECKOUT_BRANCH)
the following can be a nice trick, if most people are just going to be building the kernel, and not changing its sources:
# If we don't have KERNEL_DEEP_CLONES set in our environment, then we want # a shallow clone - this *much* reduces the time it takes to clone the # kernel sources, but then means we can't "muddle push" from it. # # Users can set KERNEL_DEEP_CLONES by, for instance, doing: # # export KERNEL_DEEP_CLONES=yes # # in their .bashrc. # if 'KERNEL_DEEP_CLONES' not in os.environ: pkg.set_checkout_vcs_option(builder, Label(LabelType.Checkout, 'kernel'), shallow_checkout=True)
If you’re using
u-boot, then something like the following may also be needed. I’m not bothering to show the description foru-bootitself.# Building a kernel image suitable for use with u-boot depends on the # mkimage program, provided by u-boot, so our kernel build depends on it rule = depend.depend_one(None, Label(LabelType.Checkout, 'kernel', 'base', LabelTag.Configured), Label(LabelType.Package, 'u-boot', 'boot', LabelTag.Installed)) builder.ruleset.add(rule) # We also want to tell the kernel build what architecture and # configuration file it should use. pkg.append_env_for_package(builder, 'kernel', ['base'], 'TARGET_CPU', TARGET_ARCH) pkg.append_env_for_package(builder, 'kernel', ['base'], 'TARGET_KERNEL_CONFIG', TARGET_KERNEL_CONFIG)
If other packages need to know the kernel label, then give it to them “by hand” - for instance, for a notional package
driverXX:pkg.append_env_for_package(builder, 'driverXX', ['drivers'], 'KERNEL_PACKAGE_LABEL', str(Label(LabelType.Package, 'kernel', 'base', LabelTag.PostInstalled)))
Finally, a Makefile.muddle that looks something like:
# Build a kernel. # # We put a couple of useful scripts in the obj dir: # # do_menuconfig - does a 'make menuconfig' with all the right options. # do_install_new_config - copies the current config back to the source # directory. KERNEL_SRC=$(MUDDLE_SRC) KERNEL_BUILD=$(MUDDLE_OBJ_OBJ) MAKE_CMD=$(MAKE) -C $(KERNEL_SRC) O=$(KERNEL_BUILD) ARCH=arm \ CROSS_COMPILE=$($(TARGET_CPU)_PFX) UBOOT=$(shell $(MUDDLE) query dir package:u-boot{boot}/*) UBOOT_TOOLS=$(UBOOT)/u-boot/u-boot-tools all: PATH=$$PATH:$(UBOOT_TOOLS) $(MAKE_CMD) uImage $(MAKE_CMD) INSTALL_MOD_PATH=$(MUDDLE_INSTALL) modules install: mkdir -p $(MUDDLE_INSTALL)/boot install -m 0744 $(KERNEL_BUILD)/arch/$(KERNEL_ARCH)/boot/uImage $(MUDDLE_INSTALL)/boot/uImage $(MAKE_CMD) INSTALL_MOD_PATH=$(MUDDLE_INSTALL) modules_install $(MAKE_CMD) INSTALL_HDR_PATH=$(MUDDLE_INSTALL) headers_install $(MAKE_CMD) INSTALL_FW_PATH=$(MUDDLE_INSTALL)/firmware firmware_install config: -mkdir -p $(KERNEL_BUILD) echo '$(MAKE_CMD) menuconfig' > $(KERNEL_BUILD)/do_menuconfig chmod +x $(KERNEL_BUILD)/do_menuconfig echo 'cp $(MUDDLE_OBJ_OBJ)/.config $(KERNEL_SRC)/$(TARGET_KERNEL_CONFIG)' >$(KERNEL_BUILD)/do_install_new_config chmod +x $(KERNEL_BUILD)/do_install_new_config install -m 0644 $(KERNEL_SRC)/$(TARGET_KERNEL_CONFIG) $(MUDDLE_OBJ_OBJ)/.config $(MAKE_CMD) oldconfig clean: $(MAKE_CMD) clean distclean: rm -rf $(MUDDLE_OBJ)(if you’re very luck I’ve got that right - this is a generalisation of some more specialised makefiles, so I’ll not be surprised if it has a bug or so).
How do I change my kernel configuation?¶
This depends on whether one means temporarily or permanently...
Typically, we recommend building the kernel out-of-tree.
Thus, given a kernel package called package:kernel{base}, and building for
architecture arm, one can do:
cd obj/kernel/base/obj
make menuconfig ARCH=arm
(or gconfig or whatever one prefers as the interface - menuconfig is
really the worst choice)
This will create an updated .config in that directory, and doing muddle
rebuild kernel{base} should then rebuild using that configuration.
Beware that muddle distrebuld kernel{base} would do a reconfigure first,
which will obey the configure target in your Makefile.muddle, which is
probably copying in the (unchanged) .config from somewhere else...
And the two scripts do_menuconfig and do_install_new_config propagated
by the Makefile.muddle in the previous section may also be of use.
How do I update a shallow checkout?¶
Shallow checkouts (or clones) were discussed in How do I build my kernel?.
In older versions of muddle, muddle pull refused to update shallow
checkouts, so if a change occurs, it was necessary to retrieve it by hand.
Newer versions of muddle will allow muddle pull (and muddle merge),
but still forbid muddle push (because git won’t allow it).
If you do need to update a shallow checkout, it is simplest to re-checkout as
a “full” checkout, and then carry on as normal. For instance, edit the
build description to remove the “shallow” flag for the checkout, and then
(assuming we’re working on src/linux/kernel):
$ cd src/linux
$ mv kernel kernel.save # remove the directory (but save it just in case)
$ muddle uncheckout kernel # to tell muddle the checkout has gone away
$ muddle checkout kernel # to check it out again
$ rm -rf kernel.save # we no longer need the saved directory
How can I make sure the correct toolchain is available?¶
Let us assume you have:
ARM_TOOLCHAIN = "/opt/toolchains/arm-2010q2"
to set up appropriate constants.Then later on (in your describe_to()
function), you can do:
if not os.path.exists(ARM_TOOLCHAIN):
raise GiveUp("Required toolchain %s not present"%ARM_TOOLCHAIN)
This is rather horrible, but may be less worse than the alternative.
Do you have a picture of a label?¶
Why, yes I do. Here is a label without domains (a “normal” label):
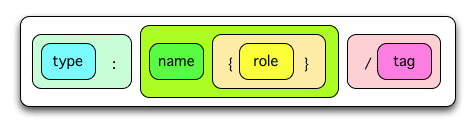
and here is a label with domains:
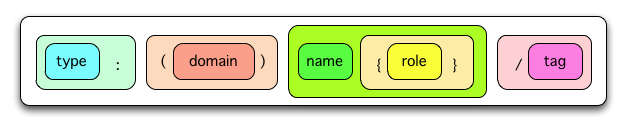
There’s even an attempt to show how these relate to the build sequence:
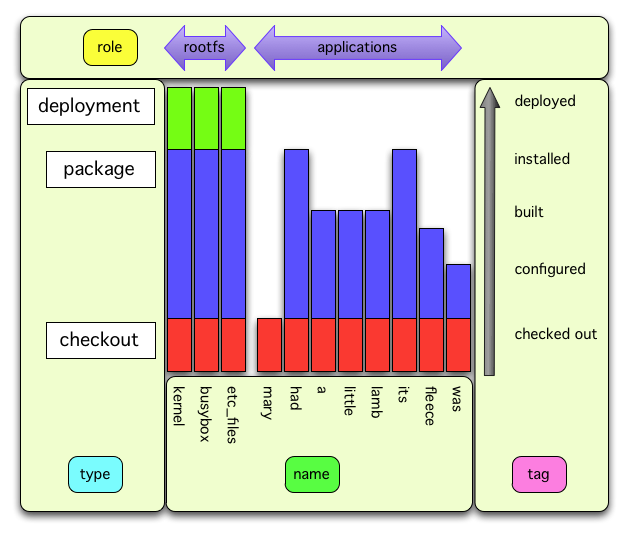
although I’m not entirely sure if that’s helpful or not.
Mechanics: how “promotion” of subdomain labels works¶
Warning
This is a note on the techincal innards of muddle, written in part for my own consumption. Please feel free to ignore it.
The code being discussed here is centred around functions inmuddled/mechanics.py.
When muddle includes a subdomain (via the include_domain() function), it
has to change all the labels in the subdomain (e.g., checkout:fred/*) into
valid, equivalent labels in the including domain (so,
checkout:(subdomain)fred/*).
The basic approach is that the function include_domain() calls
_new_sub_domain() to do nasty underhand things to the labels in the
subdomains dependency tree, and then merges the subdomain dependency tree into
the main tree.
To allow this, every entity that might be hoarding labels (using them in
sets or list or dictionaries or whatever) must have a way of returning all
of those labels. For Actions, this method is called _inner_labels().
So _new_sub_domain() retrieves labels from various Well Known Places within
the subdomain’s Builder, and from all of the actions, and from the
dictionaries managed for that subdomain by db.py, and puts them into a
single grand list.
We rely on the fact that we have every label - so for instance, we might have a list starting and ending like:
<obj id 99> "checkout:fred/*"
<obj id 1274> "checkout:marshmallow/checked_out"
<obj id 321> "package:wholemeal{x86}/built"
...
<obj id 99> "checkout:fred/*"
...
<obj id 5823> "checkout:fred/*"
...
In this list we note that: (a) we have more than one occurrence of object id
99 (object ids are obviously made up for this purpose and do not represent
real objects), and that we also have two different objects that represent
checkout:fred/* - these will compare as equal, of course. We don’t care
if we have more than one occurrence of the identical object, but we really
do care that we have at least one occurrence of every non-identical label
object.
The next bit is very simple and slightly horrible.
We know all of these label objects are from the subdomain, and we want to make them correct for the main domain. So we:
- Go through the list and mark each label object “unswept”. Doing this more than once on the same label object is alright, we can’t make them any more unswept.
- Go through the list and for each label object, if it is still marked
“unswept”:
- amend the
domainfield to add in the subdomain’s name - so a label calledcheckout:fred/*would becomecheckout:(subdomain)fred/*, and a label calledcheckout:(earlier)jim/*would becomecheckout:(subdomain(earlier))jim/*. - undo the “unswept” marker
- amend the
Once we’ve done that, we’ve promoted every single label to the new domain, in-situ.
All that then remains is for include_domain() to merge all the rules,
dictionaries and so on into the main domain. We can then discard the old
Builder, since they’re no longer of any interest.